

以后如果我写学术博客名字就叫word salad and concept soup
(前)匿名洋葱
转嘟

天呐天呐,特别喜欢hobo weeks这个365天坚持小戳,原来官网可以自行下载打印!有A6 A5和weeks尺寸!
使用例图cr logo
官网:https://www.1101.com/store/techo/en/download/#detail-1-365keizoku
(前)匿名洋葱
转嘟

她是海葵目的“小葵(アネモ)”。
是头部装备店“御头堂(おかしら堂)”的员工。
最近迷上了哥特金属风格的乐队,服装的爱好好像也稍微改变了。
听说还有鱿鱼须商城的管理和装饰武器的工作,赚的钱全部都用在了爱好上。
旁边的是克氏海葵鱼“Kumano”。
(前)匿名洋葱
转嘟

desuwa的起源十分女权desuwa!
⬇️
【日语里的"跌丝袜"到底是个啥-哔哩哔哩】 https://b23.tv/tVKr9AZ
(精神状态十分稳定)
只要!教一节课!再上一节课!我就能撑过周四了!!!明天去剪头,下午50分钟的课几乎可以忽略不计,我要自由了!!!(周末限定版)这周末属于喷喷祭典!!!
(前)匿名洋葱
转嘟

(前)匿名洋葱
转嘟

剩饭炒炒还能吃——chatGPT
想必各行各业的大家对 chatGPT 都有所耳闻了吧。有拿它编论文的有拿它写剧本的有拿它改代码的,还有打算拿它代替搜索引擎的,总之被玩出了花。谁看了不惊呼机器早晚反抗人类暴政呢?
聪明的你是否会好奇这背后藏着么大秘密?为什么她会有如此惊人的效果。
顾名思义,chatGPT由两个部分组成,chat和GPT。看到这里,读者想必有了一些猜测。没错,chat是它的训练手段,GPT是它的本质。
那么什么是GPT呢?GPT是一个语言模型,它的初代诞生时间稍早于BERT,然后在之后的很长一段时间内被BERT掩盖住了光芒。原因大概是不管GPT几,对于一般人来说train起来实在是太困(烧)难(钱)了。GPT和BERT一样,都是基于Transformer的,不同的地方在于前者是用decoder train的,后者是用encoder train的。因为encoder和decoder看到的序列的差异导致了decoder train起来更难一些,但是一旦train好的话上限其实是更高的。
再简单说一下语言模型的运作方式,就是你先喂一小段文字进去,模型会根据你喂进去的文字去预测下一个最有可能出现的词(token),再把这个词跟之前的文字一起喂进去,吐出下一个最有可能出现的词。就这样一直循环。所以理论上你让它吐得越多它就会越离谱……
所以你以开始喂进去的那一小段话我们就可以把它叫做prompt,提示语。模型在做的事就是不断地续写。根据prompt的类型的不同,续写的内容可以是问题的答案,也可以是一个命题作文。
然后就到了chat的部分。openAI应该是专门写了一个chatbot用来给数据标注人员做交互。可能这样比较有参与感,写出来的语料质量也更高吧。整个训练过程叫做Reinforcement Learning from Human Feedback (RLHF),由3个步骤组成:
-第一步是准备一个prompts的数据集,标注人员给prompts写desired outputs,模型也会产生一些辅助的outputs给人修修改改。用这样的prompts-outputs数据对就可以先finetune一下GPT了。
-第二步:经过第一步之后模型已经能吐出一部分回答了,但是不是所有的回答都特别理想,这时候标注人员可以对拿到模型对同一个prompt生成的不同回答打分。根据prompt-output-score这样的数据,又可以train一个reward model(RM)来代替人工打分的这个过程。
-有了自动生成答案和自动打分的模型之后我们就可以让语言模型自己去优化了,这就是第三步。这是一个强化学习的过程,目标是让RM打的分越高越好。
总结一下,GPT这样的模型想要train到一个比较好的程度,本身就需要海量的数据和机器。再加上设计得比较精妙的训练过程和产生高质量训练数据的方式,两者一结合就达到了非常惊人的效果。他们十个月之前做的InstructGPT虽然训练过程也大差不大但是缺了个chatbot所以导致labeler标数据标得太枯燥了,质量不佳,产量也不佳,所以模型效果也就一般般了(无端猜测)。有钱真好啊……
================
Ref:
https://openai.com/blog/chatgpt/
(前)匿名洋葱
转嘟

关于chatGPT,除了象友已经提到的版权/credit和审查/监控,我觉得还有一个角度是有些立刻想到能被AI帮到的事情,比如写会议纪要、写汇报总结之类,是不是从一开始就是bullshit tasks。个人观点:如果一个会只看纪要就够了,那它根本没必要以所有人同时到场的方式开,完全可以用异步方式协作。
(作为码农,经常需要在optimize/automate某个task/step之前先质疑一下它本身的存在必要性。)
如果那个事本身的存在目的就是规训,那即便它能被AI做,也不会被允许用AI来做。如果那个事本身就是try to measure what cannot be quantified (e.g. 所谓“工作效率”),那即使AI能measure得更好更精细,也依旧是在一条错路上。
(前)匿名洋葱
转嘟

找一个三花的全黑的奶牛的橘色的猫来告别单身♫
一个狸花的全白的暹罗的美短的猫来给我伤痕♪
有猫的人有那么多♩
没有的没有几个♬
不要逮住了 手滑了 留下了单身的我♫
独自唱情歌♪
日本网络用语kw(詳しく)在我心里就是我导师的say more,虽然它意思不太一样……但是每次导师说say more,我就算有东西可说也会突然宕机,所以say more这个词有不可磨灭的阴影
(前)匿名洋葱
转嘟

NeoGroup,灵感来源于 #NeoDB,NeoDB 里几乎涵盖了豆瓣全部的书影音功能,但是唯独缺少了小组和同城功能,作为这两个功能的重度使用者,决定做点什么,所以也模仿 NeoDB,开发了一个基于 #Mastodon 登录的去中心化小组产品 #NeoGroup
https://neogrp.club/
source: https://github.com/0xasahi/neogroup
好奇妙的感觉!大概一年以前,办公室里两个人在讨论adhd,一个人说觉得自己有adhd,但不敢去测,怕自己其实没有,只是懒。我那时候连adhd是什么都不知道,现在已经完成了整个自我怀疑到手握自己的报告的过程了
(前)匿名洋葱
转嘟

(前)匿名洋葱
转嘟

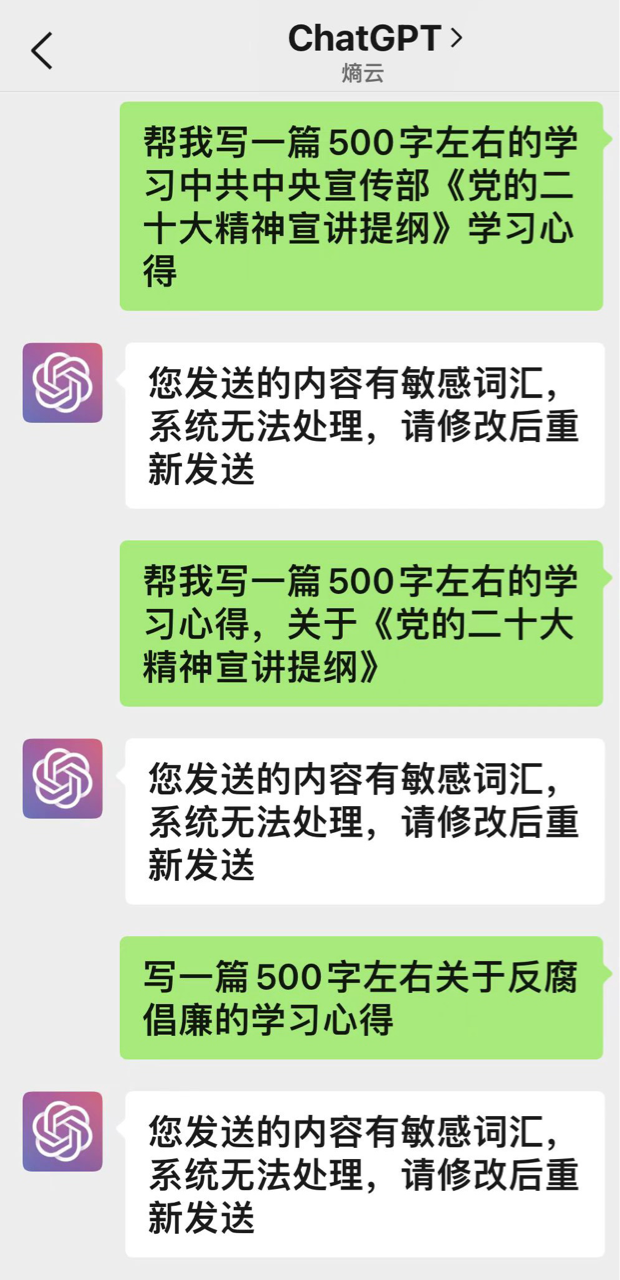
我爹问我借ChatGPT账号,想偷个懒,我问他国内中文训练量更大的版本是不是更好写那些浪费中文的玩意儿,他甩了张图:
我看着他就幻视自己小时候想抄答案发现写着略… 笑得哇…
一晚上我已经配到了好几把只有前排和只有后排的局了☹️任天堂我劝你不要不识抬举!
更新了一下R和RStudio,然后失去了我所有下载过的packages ![]()
(前)匿名洋葱
转嘟

昨天堂妹跟我出門,她說到一個我不認識的小明星塌房了,我隨口問了句怎麼塌的,她説發了白紙相關,見我沒說話,以為我不知道白紙的事,和我說,舉白紙是方便P上辱華的話,用於美國攻擊中國的宣傳(?)
原來(一部分)大眾是這樣認識白紙的

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}